עיבוד מקדים בתוכנת MATLAB הדרך הקלה והמהירה ל-Data Analytics

מכירים את הציטוט שאומר: "80% מהזמן מעבדים את הדאטה, ו-20% מהזמן מתלוננים על זה"? בפוסט הזה אני רוצה להראות לכם שזה יכול להיות ממש אחרת, בעזרת שימוש בפונקציות חדשות ומגוונות שמקלות על שלב העיבוד המקדים. אם אתם לא מכירים אותן עדיין – תתפלאו כמה זמן זה יכול לחסוך לכם בהוצאת המידע האמיתי מתוך הנתונים הגולמיים שבידיכם.
חילקתי את הפעולות ל-5 שלבים מרכזיים: חקר הנתונים, טיפול בערכים "בעייתיים", עיבוד מידע קטגוריאלי, מידע מסוג String ועבודה עם TimeSeries. ויש גם כמובן בונוסים לאורך הדרך, אז כדאי לקרוא. 😊
1. חקר הנתונים
בשלב הראשון, נרצה לקבל תמונת מצב של הנתונים שלנו. שלב זה חשוב במיוחד מכיוון שהוא עוזר לנו לענות על שאלות רבות כמו: איך נראים הנתונים שלנו? האם הם כוללים ערכים נומריים, קטגוריאליים או טקסט? האם יש בהם ערכים חסרים? האם הם מכילים רעש?
הפונקציה הראשונה שאני רוצה להכיר לכם היא פונקציית summary. פונקציה זו מחזירה מידע על כל אחת מהעמודות בטבלה. עבור ערכים נומריים היא תחזיר את סוג המשתנים, ערך מינימלי, מקסימלי וחציון. ועבור עריכם לוגיים/קטגוריאליים תחזיר את מספר התצפיות בכל אחת מהקבוצות.
להלן דוגמה של שימוש בפונקציה זו:

נראה כי באמצעות פקודה אחת נוכל להבין מה בדיוק נמצא בתוך הטבלה T!. הטבלה מכילה נתונים על 100 חולים. ניתן לראות עבור כל חולה את המגדר שלו, גיל, לחץ הדם והאם הוא מעשן.
ראינו כי הטבלה מכילה נתונים על חולים, שגילם נע בין 25 ל-50. בשלב הבא, נרצה לדעת מה פילוג החולים לפי גיל. ניתן לעשות זאת באמצעות פקודת groupsummary. הפונקציה מחזירה טבלה המכילה את מספר התצפיות עבור כל אחת מהקבוצות.
על ידי שימוש בפונקציה, נקבל את הפלט הבא:
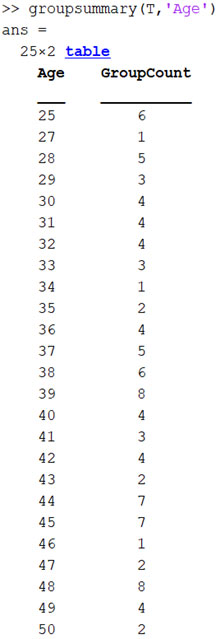
בעמודה של ה- Age, נראה כי ישנן 25 קבוצות גיל ובעמודה של ה-GroupCount נראה כמה תצפיות מיוחסות לאותה קבוצת גיל. במידה ונרצה לדעת מה לחץ הדם הממוצע עבור כל אחת מהקבוצות נוכל להשתמש באותה פקודה בצורה הבאה:
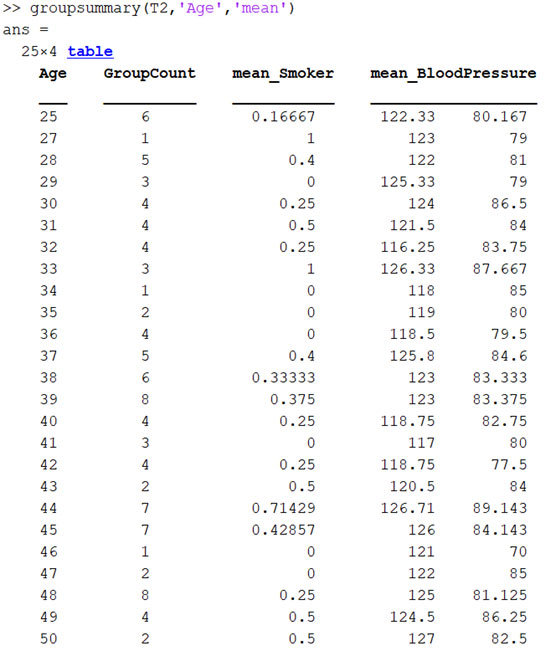
חשוב לציין, כי על מנת לקבל את הטבלה לעיל, היינו צריכים למחוק את עמודת המגדר (‘Gender’) מכיוון שלא ניתן לחשב ממוצע עבור משתנה קטגוריאלי. עשינו זאת באמצעות הפקודה:
![]()
2. טיפול בערכים בעייתיים
בדוגמא הקודמת, נראה כי הנתונים "נקיים", כלומר לא מכילים ערכים חסרים או ערכים חריגים. על מנת להמחיש לכם את ההתמודדות עם נתונים חסרים, נתבונן על הנתונים הבאים:
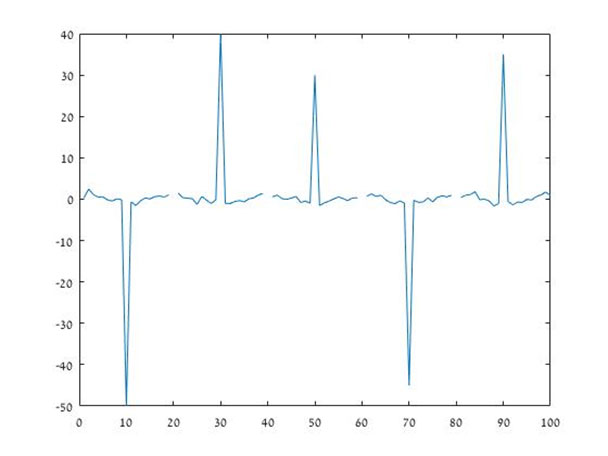
ניתן לראות שהנתונים לעיל מכילים גם ערכים חסרים וגם ערכים חריגים. אילו פונקציות יעזרו לנו להתמודד עם מצב בעייתי שכזה?
הפקודה ismissing תאפשר לנו לקבל וקטור לוגי, כאשר הערכים החסרים יהיו שווים ל-1 והשאר יהיו שווים ל-0. נוכל לאמוד את מספר הערכים החסרים באמצעות פונקציית nnz (גם sum עובד!).

כעת נצטרך להחליט מה נרצה לעשות עם הערכים האלה, נוכל:
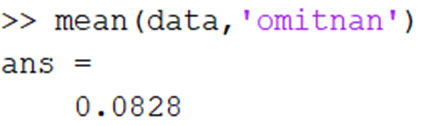
להתעלם מערכים חסרים –פונקציות מסוימות יחזירו לנו ערכי NaN במידה והנתונים שלנו מכילים ערכים חסרים, לדוגמה:
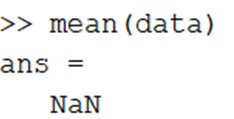
לשמחתנו, נוכל לחשב את הממוצע מבלי לשנות את המשתנה שנמצא ב-workspace בעזרת flag של ‘omitnan’ שמאפשר להתעלם מה-NaN שנמצאים בדאטה:
למחוק ערכים חסרים – ניתן לעשות זאת באמצעות פקודת rmmissing.
שימו לב! מחיקת ערכים תקטין את גודל הווקטור, ולכן יש למחוק בזהירות.
להחליף ערכים חסרים – ניתן להחליף ערכים חסרים (וכך לשמר את גודל המשתנה) לערכים אחרים באמצעות פונקציית fillmissing. במקרה זה, האתגר הוא למצוא את הערך שיחליף את ה-NaN. ניתן להחליף את הערכים החסרים במספר קבוע, אך בהרבה מקרים כדאי להשתמש באינטרפולציה לינארית:
![]()
לגבי עבודה עם ערכים חריגים, הפונקציות המתאימות הן: filloutliers, rmoutliers, isoutliers.
בונוס!
בגרסת R2019b התווספו ל-MATLAB אפליקציות שניתן להוסיף ל-Live Script שנקראות Live Editor tasks. האפליקציות האלה מאפשרות לבצע מספר פעולות ולחקור פרמטרים בצורה אינטראקטיבית ולאחר מכן לייצר קוד MATLAB באופן אוטומטי. השימוש באפליקציות מאפשר לצמצם את זמן הפיתוח, למנוע שגיאות ולערוך גרפים בקלות.
להלן הדגמה קצרה:
3. עבודה עם מידע קטיגוריאלי
עד כה, דיברנו אך ורק על נתונים מסוג נומרי, אך לעיתים נצטרך לטפל במשתנים קטגוריאליים. משתנה קטגוריאלי הינו משתנה שערכו שייך לקבוצה מתוך סט סופי של קבוצות או קטגוריות. ניתן להגדיר משתנים קטגוריאליים בצורה הבאה:

ניתן לראות שקיימות 6 תצפיות במשתנה A, אבל בפועל קיימות 3 קבוצות שונות. כמו כן, פקודת categories מאפשרת להציג את הקבוצות של המשתנה:

ניתן לאחד שתי קבוצות באמצעות פונקציות mergecats:

צמצמנו את מספר הקבוצות מ-3 ל-2, ולכן ייתכן שנרצה להגדיר מחדש את שמות הקבוצות. ניתן לעשות זאת בעזרת פקודת renamecats:

כעת, משתנה C מכיל 6 תצפיות של 2 קבוצות שונות. על מנת לספור את מספר התצפיות עבור כל אחת מהקבוצות, ניתן להשתמש בפונקציות countcats:
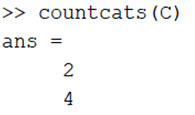
בדומה לסידור ומחיקת משתנים בטבלה שראינו לעיל, ניתן להשתמש ב-removecats למחיקת קטגוריה או reordercats לשינוי סדר הקטגוריות.
4. מידע מסוג string
בגרסת R2016b התווסף טיפוס מידע חדש ב-MATLAB לעבודה עם טקסט שנקרא string.
String Array מאחסן פיסות טקסט ומספק מערך של פונקציות לעבודה עם טקסט כנתונים. ניתן להוסיף אינדקס למערכים, לעצב אותם ולשרשר אותם בדיוק כמו שאנחנו יכולים לעשות עם מערכים מכל סוג אחר. ניתן גם לגשת לתווים במחרוזת ולהוסיף טקסט למחרוזות באמצעות חיבור פשוט (+). כדי לסדר מחדש מחרוזות בתוך מערך מחרוזות, נשתמש בפונקציות כמו split, join ו-sort.
נמחיש את השימוש ב-string באמצעות דוגמא. נבנה מערך של 5 משתנים שמורכבים משם פרטי ושם משפחה. נרצה לסדר את השמות כך ששם המשפחה יופיע ראשון ויסודר לפי א'-ב'.
בשלב הראשון, ניצור מערך של string בעזרת גרשיים ונפריד בין השם פרטי לשם משפחה ע"י פונקציית split:

נחליף את עמודות השמות כך ששמות המשפחה יהיו בעמודה הראשונה, ונוסיף פסיק אחרי כל שם משפחה:

נאחד כעת בין השמות הפרטיים לשמות המשפחה בעזרת פונקציית join. הפונקציה מוסיפה בצורה אוטומטית תו רווח בין המילים המאוחדות.

נמיין את השמות כך שיהיו בסדר אלפביתי בעזרת פונקציית sort:

נראה כי העבודה עם דאטה מסוג string היא מאוד פשוטה ואינטואיטיבית!
5. עבודה עם סדרות זמן
בגרסת R2016b התווסף טיפוס מידע חדש לעבודה ב MATLAB-שנקרא .Timetable על ידי שימוש ביכולת זו, תוכלו לאגד מידע שכולל גם יחידות זמן, ולנהל את כל המאגר שלכם בצורה יעילה יותר. ניתן להמיר מ-tables ל-timetable באמצעות פקודת table2timetable ובכך להשתמש בפונקציות ייעודיות לעבודה עם זמנים. תוכלו לגלות באילו פונקציות מדובר בפוסט זה.
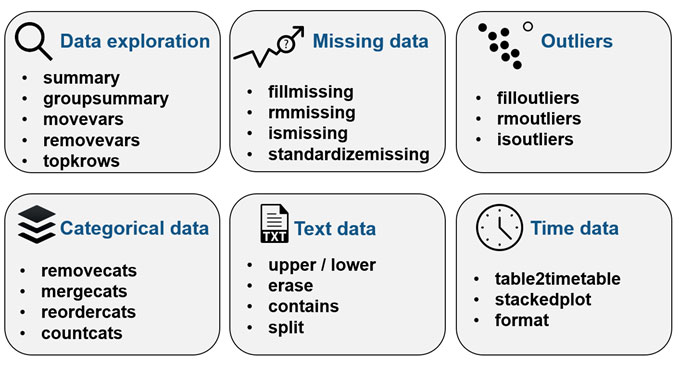
לסיכום, ריכזתי לנוחיותכם את הפונקציות השונות שצוינו לעיל בטבלה הבאה:
מקווה שכעת לאחר קריאת הפוסט תוכלו להגיד ש –
"100% מהזמן מעבדים את הדאטה, ו-0% מהזמן מתלוננים על זה" 😊
בהצלחה!