למידת חיזוק – Reinforcement Learning
למידת חיזוק (RL) היא חלק מתחום למידת המכונה שפרץ לחיינו בשנים האחרונות הודות ליכולות החישוב הנדרשות שהפכו לנגישות בימינו.
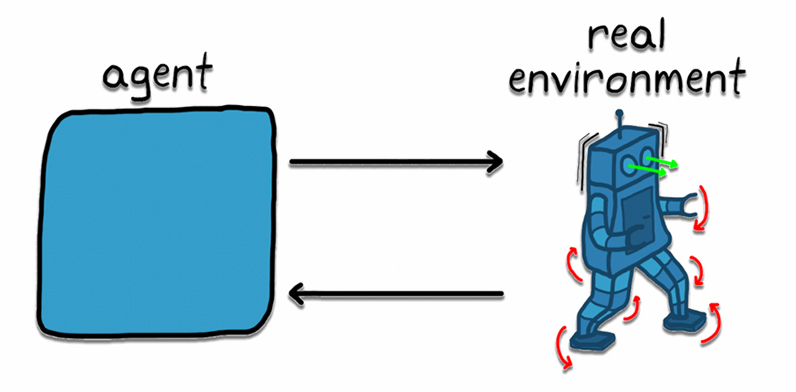
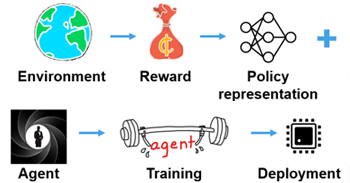
העקרון של למידת חיזוק שונה בבסיסו מלמידה מונחית או בלתי מונחית לאור העובדה שהיא אינה ניזונה מדאטה קיים, אלא היא מבצעת חקירה על עצמה בעזרת מודל סימולציה / מערכת אמיתית בכך שלאחר כל איטרציה מתקבלת תוצאה שעוזרת למערכת לקבוע כיצד עליה לתפקד וחוזר חלילה.
אמחיש את נושא למידת המכונה באופן הבא: למידה מונחית: בדומה לתינוק שאך נולד ואינו יודע להבחין בין חפצים עד אשר מלמדים אותו מהו אור ומהי מכונית, למידה בלתי מונחית: התינוק מבחין שכאשר הוא בוכה הוא מקבל דברים, למידת חיזוק: אנו לא מלמדים את התינוק ללכת אלא הוא לומד ללכת בעצמו בעזרת ניסוי ותהייה עד אשר הוא מצליח לפתח זאת לכדי ריצה, התינוק לומד שאם הוא נופל אז הוא עשה דבר שאינו תקין, בעוד אם הוא הצליח לעמוד במקום הוא מנסה להיאחז בזה כי הוא בדרך הנכונה.