לפרק את הקופסא השחורה:
איך נדע שאפשר לסמוך על תוצאות מודל ה-AI שלנו?


בניתם מודל AI, אימנתם אותו ואתם נהנים לבדוק עם דאטה חדש מהם הניבויים שהמודל מפיק עבורו. האם העבודה מסתיימת כאן? אז למרות שזה כיף לראות כיצד מודל יודע להבדיל בצורה מרשימה האם מדובר בחתול, עכבר או דביבון – היום אני באה לטעון… שלא, שהעבודה לא נגמרה כאן!
בשלב הבא, נרצה להבין למה מודל ה-AI שלנו הגיע להחלטה המסוימת שהגיע אליה?
חשוב שנשאל שאלות כמו – למה המודל לא בחר בניבוי אחר? מתי המודל מצליח להגיע לדיוקים טובים? מתי הוא נכשל? מתי אוכל לסמוך עליו? איך אוכל לתקן את השגיאות של המודל?
במיוחד בתעשיות כמו תעשיית הפיננסים, הנהיגה האוטונומית או בתעשיית המכשור הרפואי, אשר נדרשות בעמידה בתקנים רגולטורים מאוד מחמירים – חשוב שהחברות השונות יוכלו לסמוך על המודלים שהן מפתחות.
וזה בהחלט קשה לסמוך על מודל שאנחנו לא יודעים להסביר למה הוא קבע מה שקבע.
הרבה פעמים קוראים למודלי AI קופסא שחורה, כי לא תמיד דרך הצגת הדאטה בהם היא אינטואיטיבית, וכתוצאה מכך, קשה להבין איך הם עובדים.
תחום מאוד חשוב שהולך וצובר תאוצה בתקופה האחרונה הוא Explainable AI / Interpretable AI, או בקיצור XAI (eXplainable Artificial Intelligence) אשר מחפש דרכים ושיטות להבין את המכניקה שמאחורי הקופסא השחורה, ולעזור לנו לדעת להצביע על המוקדים אשר היוו עניין מוגבר בתהליך הלמידה עבור מודל ה-AI, וכן לתת לנו רמזים לגבי נקודות התורפה של מודל ה-AI שבנינו.
קיימות 2 דרכים עיקריות להשגת אינדיקציות להסבר המודלים מבפנים:
- על ידי תכנון ופיתוח מודלים שניתנים לפענוח עצם הארכיטקטורה הפנימית שלהם (inherently interpretable models). אחד מסוגי המודלים הכי פופולרי תחת הגדרה זו הוא עצי החלטה למשימות של קלאסיפיקציה או רגרסיה. מהטבע של איך שעצי החלטה נבנים, האלגוריתם של המודל יודע לבחור את הפיצ'רים החשובים ביותר, את ערכי הסף שחושבו בכל צומת החלטה וכן לשרטט את הדרך שהובילה את העץ להחלטה כלשהי.

- על ידי הפקת הסברים Post hoc – בצורה רטרואקטיבית, אחרי שהמודל החזיר תוצאות.
כך נוכל למשל במקרה של תמונות, לבחון אילו אזורים בתמונה בוהקים בצורה החזקה ביותר ומעידים על כך שהיוו לאזורים החשובים ביותר לקלאסיפיקציה שהרשת ביצעה.
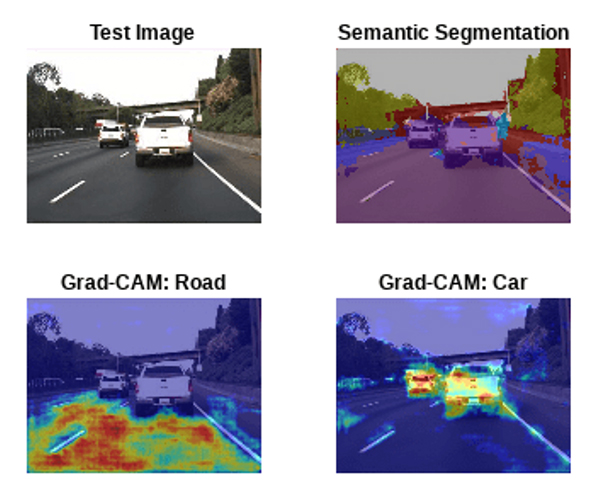
תוצאות post hoc לפי שיטת Grad-CAM לצורך ביצוע סגמנטציה סמנטית לתמונה
בתמונה הבאה, תוכלו לראות פריסה של השיטות השונות שניתן ליישם ב-MATLAB כדי להבין את המודל שלנו בצורה טובה יותר.
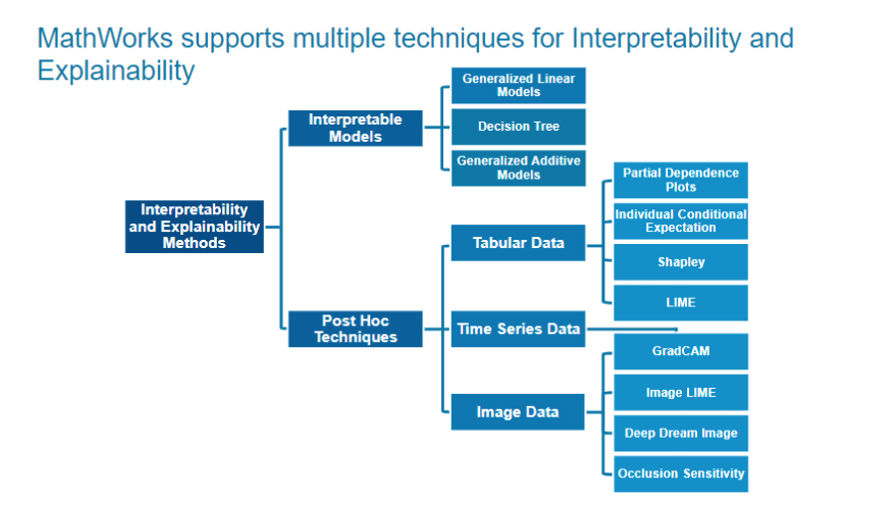
ניתן לראות כי מעבר לדרך בה אנחנו מעוניינים לנקוט (ניתוח Post hoc או עבודה עם מודלים שניתנים לפענוח פנימי), חשוב לתת את הדגש לסוג הדאטה שאנחנו עובדים איתו.
כך למשל, אם אנחנו עובדים עם תמונות, נוכל למצוא שימוש בשיטות כמו Grad-CAM, Image LIME, Occlusion Sensitivity ועוד. תוכלו לראות בלינק הבא שימוש שיטות נוספות דרך דוגמא.
לעומת זאת, אם הדאטה שלנו הוא דאטה טבולרי (טבלאות), סביר שנמצא שימוש בשיטות כמו Shapley Values, LIME, ועוד. תוכלו לראות בלינק הבא כיצד ניתן ליישם את שיטת LIME ב-MATLAB על מנת לפענח את התוצאות של רשת עמוקה.
לסיכום, יש צורך אמיתי בפיזור הערפל בכל הקשור לקופסאות ה-AI השחורות, וככל ששיטות Explainability יפותחו עוד ועוד ותהינה בשימוש על ידי קהילת מפתחי ה-AI, כך החשש לאמץ פתרונות מבוססי AI בתהליכי הפיתוח ילך ויקטן; וכך תוכלנה חברות שונות בתחומי המדיקל, הנהיגה האוטונומית, הביטחון והפיננסים, לפתח מערכות AI מתקדמות, בטוחות ואמינות, אשר עומדות בתקני רגולציה מחמירים כמו EUROCAE או ה-FDA הדרושים להשגת סרטיפיקציה (רשיון) למוצרים שהן מפתחות.
למידע נוסף: